결과
내용을 작성하기에 앞서 결과적으로는 좋은 성능의 예측 모델을 만들지 못했다.
AutoML을 사용해 다양한 Feature(장 초반 생성되는 패턴)를 학습시켜 장 마감 지수를 예측하려고 했지만, 거의 예측을 하지 못하는 모델이 학습됐다.
접근
보통 시계열이나 회귀 문제로 접근하는 주식 시장의 흐름을 패턴에 맞춰 대응한다는 개념으로 분류 문제로 접근해보기로 했다.
현재 분석 가능한 데이터는 다음과 같다.
- 거래소_선물지수 1분봉
- 외국인거래소_매도금액 1분봉
- 외국인거래소_매수금액 1분봉
- 외국인거래소_선물매도량 1분봉
- 외국인거래소_선물매수량 1분봉
위 목록의 데이터들은 2017년 1월부터 2021년 3월 초의 장 시작부터 장 마감까지 시가, 고가, 저가, 종가로 이루어져있다.
거래소_선물지수_1분봉.csv
1 | |
외국인거래소_매수금액_1분봉
1 | |
각 컬럼 "Date","Time","Open","High","Low","Close","Up","Down"는 날짜,시간,시가,고가,저가,종가,상승체결,하락체결을 의미한다.
모든 데이터들은 1분봉으로 이루어져 있기 때문에 시가, 고가 등등 1분동안 크게 변화가 없으므로 시가 정보인 Open 데이터만 분석에 사용한다.
거래소 선물지수 데이터는 그대로 사용하고 외국인 거래량, 거래액은 거래량을 사용하되 순 거래량을 계산해서 사용하기로 한다.
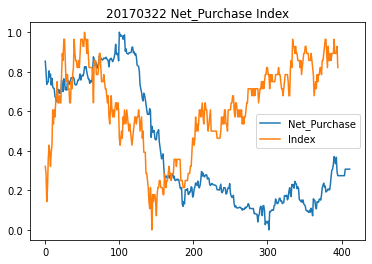
선물지수, 순거래량 차트
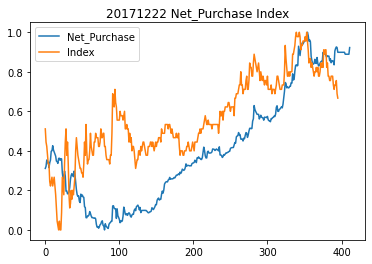
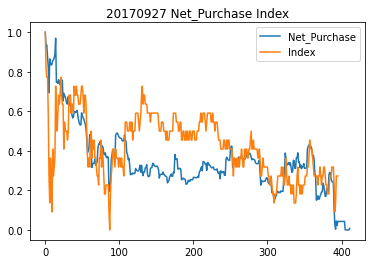
Net_Purchase는 외국인 순 거래량, Index는 선물지수이다.
데이터 처리
전체 데이터 중 일부 데이터를 사용해 두 지수를 비교하였고 값의 단위가 다르기 때문에 sklearn.preprocessing의 MinMaxScaler를 사용해 정규화를 진행했다.
두 데이터에서 학습 데이터를 추출해야 하는데 위에서 말했던 것 처럼 분류의 형태로 접근할 것이다.
장 초반에 생성되는 지수 패턴과 순매수량 패턴을 feature로 잡고 장 마감시 지수가 패턴이 끝날 때 지수보다 1%이상 상승했으면 Positive, 아니라면 Negative로 보고 이항 분류 형태의 데이터를 만들 것이다.
get_train_data
1 | |
하루에 생성되는 데이터를 결합하여 한 row로 생성할 것이고 pattern_end_position부터 pattern_end_position 까지 생성되는 데이터를 패턴으로 판단하여 feature로 row에 추가한다.
기본값이 0 ~ 30으로 잡혀있는데 이는 장 시작 9:00 부터 장 마감 16:20 까지 420여개(종종 몇개의 분봉은 넘어가는 데이터도 존재함)의 분봉이 존재하므로 position값 1당 1분으로 봐도 무방하다.
즉 장 시작 30분간의 패턴을 학습에 사용되는 Feature로 사용한다는 뜻이다.
그 다음 장 마감시 지수가 장 초반 (패턴을 읽은 뒤 : 장 시작 30분 후) 지수보다 1%이상 상승했다면 Positive(1)로 아니라면 Negative(0)로 잡고 Label을 생성한다.
1 | |
마지막으로 모든 데이터를 MinMaxScaler로 정규화 하고 학습용 데이터를 생성한다.
생성된 학습 데이터는 아래와 같은 형태다.
1 | |
한 row당 하루의 장 흐름 데이터이며
col 0~29은 외국인 순 거래량 분봉 데이터, 30 ~ 59은 선물 지수 분봉 데이터, 마지막 60은 1%이상 상승했는지를 나타내는 Label이다.
모델 생성
데이터는 준비되었으니 준비된 데이터로 학습을 진행한다.
학습 이전에 학습용 데이터와 테스트용 데이터를 7:3 비율로 나눈다.
1 | |
학습에 사용할 라이브러리는 AutoKeras이다.
AutoKeras의 사용법은 간단하다. 학습시킬 데이터의 형태에 맞는 클래스를 선택해서 최대 반복 횟수와 epochs만 지정해주면 학습을 반복하면서 가장 성능이 좋은 모델을 찾아낸다.
만약 더이상 성능이 개선될 여지가 없으면 조기 종료된다.
1 | |
1 | |
54번의 반복후에 91%의 정확도를 가진 모델이 생성되었다.
평가
내부적으로 학습 데이터를 나누어 (20%) 검증에 사용하지만 따로 분리해 둔 테스트용 데이터로 성능을 다시 테스트 해본다.
1 | |
1 | |
평균 정확도는 85%이지만 자세히 살펴보면 Positve을 예측하는 정도, 즉 1% 이상 오르는지에 대한 예측 성능은 낮다.
Precision, Recall, F1-Score 전부 0.5 이하의 점수가 나온다.
즉 지금 데이터로는 장 마감시 지수 예측을 거의 못한다는 뜻이다.