Learning Spark
아파치 스파크란 무엇인가?
아파치 스파크는 범용적이면서도 빠른 속도로 작업을 수행할 수 있도록 설계한 클러스터용 연산 플랫폼이다.
스파크는 맵리듀스 모델을 대화형 명령어 쿼리나 스트리밍 처리 등이 가능하도록 확장하였다. 스파크가 속도를 높이기 위하여 제공하는 중요한 기능 중 하나는 연산을 메모리에서 수행하는 기능이지만, 설령 복잡한 프로그램을 메모리가 아닌 디스크에서 돌리더라도 맵리듀스보다는 더욱 뛰어난 성능을 보여준다.
범용적이라는 면에서 스파크는 기존에 각각 분리된 분산 시스템에서 돌아가던 배치 애플리케이션, 반복 알고리즘, 대화형 쿼리, 스트리밍같은 다양한 작업 타임을 동시에 커버할 수 있게 설계되었다. 이런 워크로드들을 단일 시스템에서 지원하게 됨에 따라 스파크는 실제의 데이터 분석 파이프라인에서도 서로 다른 형태의 작업을 쉽고 저비용으로 연계할 수 있게 해준다.
스파크는 고수준에서 접근하기 쉽게 설계되어 있어서 파이썬, 자바, 스칼라, SQL API 및 강력한 라이브러리를 내장해 지원한다. 또한 다른 빅데이터 툴과도 매우 잘 연동되어 있다. 특히 스파크는 하둡 클러스터 위에서도 실행 가능하며, 카산드라를 포함하는 어떤 하둡 데이터 소스에도 접근이 가능하다.
- 스파크는 클러스터용 연산 플랫폼이다.
- 인메모리 방식으로 연산을 수행하며 맵리듀스보다 뛰어난 성능을 보여준다.
- 다른 형태의 작업(배치, 반복, 쿼리, 스트리밍 등)과 쉽게 연계할 수 있다.
- 고수준의 라이브러리를 지원하며 하둡 데이터 소스에 쉽게 접근 가능하다.
통합된 구성
스파크 프로젝트는 밀접하게 연동된 여러 개의 컴포넌트로 구성되어 있다. 그 핵심에서 스파크는 다수의 작업 머신이나 클러스터 위에서 돌아가는 많은 연산 작업 프로그램을 스케줄링하고 분배하고 감시하는 역할을 한다. 스파크의 핵심 엔진은 앞에서도 언급했듯이 빠르고 범용적이라서 SQL이나 머신 러닝 같은 다양한 워크로드에 특화된 여러 고수준 컴포넌트를 실행할 수 있게 해준다. 이 컴포넌트들은 일반적인 소프트웨어 프로젝트에서 라이브러리들을 연동해 쓰듯이 사용자가 컴포넌트들을 연동해 쓸 수 있게 상호 호환되도록 설계되었다.
이처럼 밀접하게 컴포넌트를 연동하는 설계 원칙에는 몇 가지 장점이 있다. 일단 S/W구성에 포함된 모든 라이브러리나 고수준 컴포넌트들이 하위 레이어의 성능 향상에 의해 직접적으로 이익을 볼 수 있다. 예를 들어, 스파크 핵심 엔진을 최적화한다면 SQL이나 머신 러닝 라이브러리들도 자동으로 속도가 빨라진다. 또한 5 ~ 10 개의 개별 S/W를 실행 하는 것 대신 하나만 돌리면 되니 프로그램들을 운영하는 비용을 최소화 할 수 있다.
스파크의 구성 목록에 새로운 컴포넌트가 추가된다고 하더라도 스파크를 사용하는 모든 기업이나 조직에서 별도의 설치에 대한 노력 없이 이 컴포넌트를 바로 써 볼 수 있다.
마지막으로, 밀접한 컴포넌트 연동의 가장 큰 장점 중 하나는 서로 다른 데이터 처리 모델을 깔끔하게 합쳐서 하나의 애플리케이션으로 만들 수 있다는 점이다.
예를 들어, 스파크에서 스트리밍 소스를 통해 들어오는 데이터를 실시간으로 분류하는 머신러닝 애플리케이션을 만들었다고 할 때, 동시에 분석가들은 결과 값에 실시간으로 SQL 질의를 날릴 수 있으며 능력이 되는 데이터 엔지니어나 과학자들이라면 그 데이터에 즉각적인 분석을 하기 위해 파이썬 셀을 통해 접근할 수 있다. 다른 사람들은 단독 배치 애플리케이션을 실행하기 위해 데이터에 접근할 수도 있다. 이 모든 상황에 대해서 IT 팀은 오직 하나의 시스템만 관리하면 된다.
스파크 구성
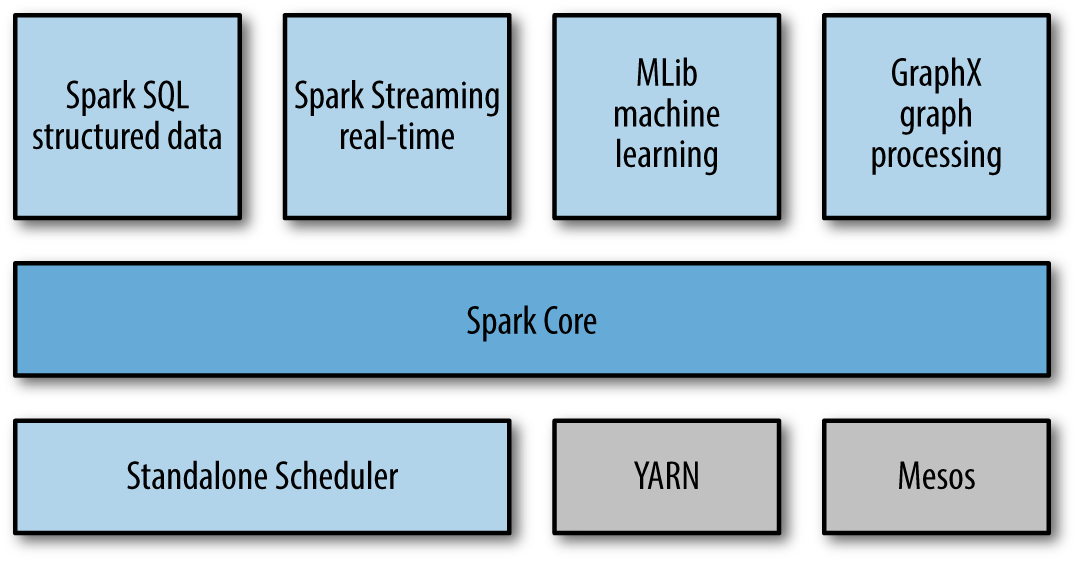
스파크 코어
스파크 코어는 작업 스케줄링, 메모리 관리, 장애 복구, 저장 장치와의 연동 등등 기본적인 기능들로 구성된다.
스파크 코어는 탄력적인 분산 데이터세트(RDD Resilient Distributed Dataset)를 정의하는 API의 기반이 되며, 이것이 주된 스파크 프로그래밍 추상화의 구조이다.
RDD는 여러 컴퓨터 노드에 흩어져 있으면서 병렬 처리될 수 있는 아이템의 모음을 표현한다.
스파크 SQL
스파크 SQL은 정형 데이터를 처리하기 위한 스파크의 패키지이다.
SQL뿐만 아니라 하이브 테이블, 파케이, JSON 등 다양한 데이터 소스를 지원한다. 특히 아파치 하이브의 SQL 변형(HQL)을 써서 데이터에 질의를 보낼 수 있다.
또한 SQL과 복잡한 분석 작업을 서로 연결할 수 있도록 지원한다. 그 덕분에 개발자가 단일 애플리케이션 내에 파이썬, 자바, 스칼라의 RDD에서 지원하는 코드를 데이터 조작을 위해 SQL 쿼리와 함께 사용할 수 있다.
우수한 컴퓨팅 환경에서라면 스파크가 제공하는, 이 강한 연동 능력은 스파크 SQL을 여느 다른 오픈 소스 데이터 웨어하우징 도구들과 차별화시켜 준다.
스파크 스트리밍
스파크 스트리밍은 실시간 데이터 스트림을 처리 가능하게 해 주는 스파크의 컴포넌트이다. 여기서 데이터 스트림이라는 것은
- 제품 환경의 웹 서버가 생성한 로그 파일
- 웹 서비스의 사용자들이 만들어내는 상태 업데이트 메세지들이 저장되는 큐 같은 것들도 해당된다.
스파크 스트리밍은 스파크 코어의 RDD API와 거의 일치하는 형태의 데이터 스트림 조작 API를 지원함으로써 프로그래머들이 프로젝트에 빠르게 익숙해지게 해 준다. 그리고 메모리나 디스크에 저장되어 있는 데이터를 다루는 애플리케이션이든 실시간으로 받는 데이터를 다루는 애플리케이션이든 서로 바꿔가면서 다루더라도 혼란이 없게 해준다.
이 API들의 아랫단에서 스파크 스트리밍은 스파크 코어와 동일한 수준의 장애 관리, 처리량, 확장성을 지원하도록 설계 되어있다.
MLlib
스파크의 MLlib라는 일반적인 머신 러닝 기능들을 갖고 있는 라이브러리들과 함께 배포된다.
MLlib은 분류, 회귀, 클러스터링, 협업 필터링 등의 다양한 타입의 머신 런이 알고리즘 뿐만 아니라 모델 평가 및 외부 데이터 불러오기 같은 기능도 지원한다. 게다가 경사 하강 최적화 알고리즘 같은 몇몇 저수준의 ML 핵심 기능들도 지원한다. 이 모든 긴응들은 클러스터 전체를 사용하며 실행되도록 설계되었다.
그래프X
그래프X는 그래프를 다루기 위한 라이브러리이며, 그래프 병렬 연산을 수행한다.
스파크 스트리밍이나 스파크 SQL처럼 그래프X도 스파크 RDD API를 확장하였으며, 각 간선이나 점에 임의의 속성을 추가한 지향성 그래프를 만ㄷ르 수 있다.
또한 그래프를 다루는 다양한 메소드들 및 일반적인 그래프 알고리즘들의 라이브러리를 지원한다.
클러스터 매니저
스파크는 한 노드에서 수천 노드까지 효과적으로 성능을 확장할 수 있도록 만들어졌다.
유연성을 극대화하면서 이를 달성하기 위해 스파크는 하둡의 얀, 아파치 메소스, 스파크에서 지원하는 가벼운 구현의 클러스터 매니저인 단독 스케줄러 등 다양한 클러스터 매니저 위에서 동작할 수 있다.
다른 것들이 설치되지 않은 머신에서 스파크를 설치한다면 단독 스케줄러가 시작하기에 쉬운 선택이며, 이미 얀이나 메소드 클러스터가 있다면 스파크는 그 위에서 애플리케이션을 실행시킬 수 있도록 지원한다.
- 스파크는 여러 개의 컴포넌트로 구성되어 있으며, 그 중심에서 스파크는 스케줄링 및 분배 작업을 한다.